
#
Spring Batch : The Main Concepts

The tutorial will explain what are the main concepts in Spring Batch.
With Spring Batch, you can define and run jobs. The job may have a step or many steps. During a step, the job do something,
a particular task, named tasklet. When you define a step you can define the next step you have to execute.
1 job ---(has)--- > 1..n steps / 1..n flows
1 flow ---(has)--- > 1..n steps
1 step could : --> run a single task(named tasklet)
--> follow the READ(in)-PROCESS(in/out)-WRITE(out) pattern
This pattern is implemented when we define the steps:
step.<String, String> chunk(2)
.reader(itemReader)
.processor(itemProcessor)
.writer(itemWriter)Typically, Batch Jobs are long-running, non-interactive and process large volumes of data, more than fits in memory or a single transaction.
A job could execute steps in a defined order. We can have sequential steps and parallel steps.
We can execute some tasks (steps) when a condition is true or false. Because of these things, you can create
workflows using Spring Batch.
Sometimes, you need a step to be executed by chunks: you want to insert 100.000 rows ten times instead 1.000.000 one time.
This can be done using Spring Batch. For this reason one tasklet could have 0 .. 1 chunk.
All the information about the job executions are stored in a Database Repository. This is named JobRepository.
You can take a look at the following picture:
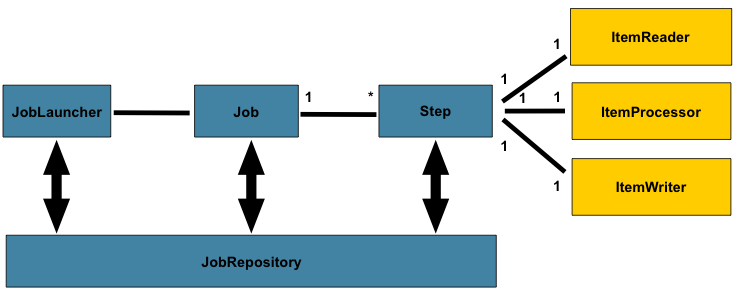
In this picture you can see that:
- all the information related to the jobs are stored in a JobRepository;
- a typical step include a read sequence (ItemReader), a process which can test/ do something with the data read before (ItemProcessor) and an write sequence (ItemWriter) which write initial/modified or other information to another source of data (to a database for instance).
The Job Repository must be configured in a database.
The jobs are started by JobLauncher. JobLauncher starts a job for a given Job & JobParameters.
The combination Job + JobParameters = JobInstance.
During the execution of a job, a context bean is created automatically: the JobExecution. The JobExecution bean is created each time a job run. When you rerun a job, a new JobExecution Bean is created.
You can use in addition a JobOperator which is an interface that provides operations for inspecting and controlling jobs, mainly for a command-line client or a remote launcher like a JMX console.
We can also define listeners to execute different code before/after chunks or Item Readers/Processors/Writer or on errors.