
#
Kafka Architecture

This tutorial explains the main concepts of Apache Kafka Server. This tutorial explains the Apache Kafka Architecture.
Apache Kafka is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications. More than 80% of all Fortune 100 companies trust, and use Kafka.
Here is the big picture of Apache Kafka Architecture :
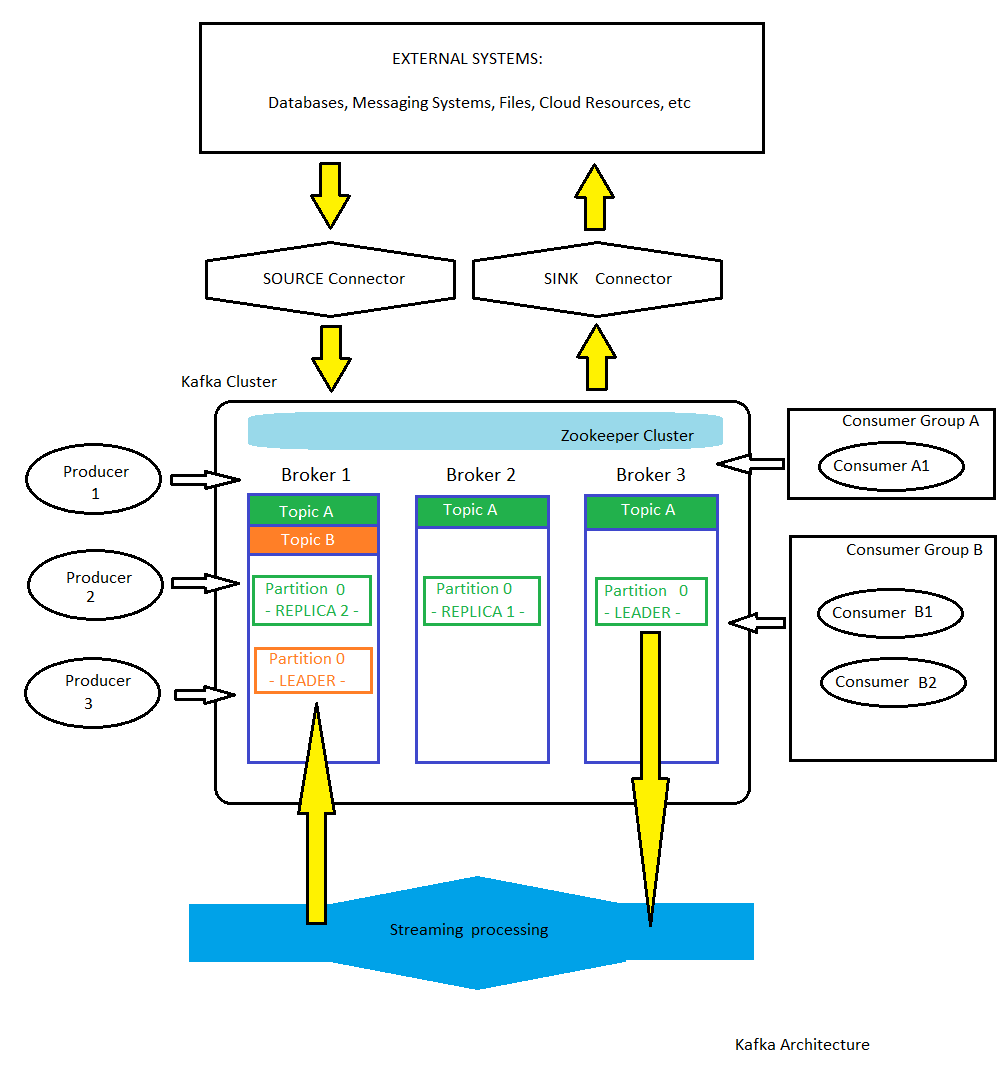
Here are some points to underline about Apache Kafka Architecture:
Apache Kafka is a publish-subscribe based durable messaging system
a
Kafka brokeris a node on the Kafka cluster, its use is to persist and replicate the dataa
Kafka producerpushes the message into the Kafka Topica
Kafka consumerpulls the message from the Kafka Topic. Each consumer is part of a specific consumer groupa
consumer groupis a set of consumers which cooperate to consume data from some topics. The partitions of all the topics are divided among the consumers in the group. As new group members arrive and old members leave, the partitions are re-assigned so that each member receives a proportional share of the partitions.Zookeeper is used to manage service discovery for Kafka Brokers that form the cluster. Zookeeper sends changes of the topology to Kafka, so each node in the cluster knows when a new broker joined, a Broker died, a topic was removed or a topic was added, etc. Future Kafka releases are planning to remove the Zookeeper dependency but as of now it is an integral part of it.
a
Kafka source connectorread messages from external systems and put the data into a Kafka topicsa
Kafka sink connectorread messages from Kafka topics and persist/put them into external systemsa
streaming processingis an application which is integrated with Kafka Cluster which read/ listen on particular topics and automatically process that data (without modifying the original data). Stream processing allows applications to respond to new data events at the moment they occur.a
topic(a logical concept) is the place where the messages are put on. Physically, the messages are put on partitions. A topic could have more partitions for increasing the throughput.
The partitions are ordered (FIFO), but the topics are not when we have more partitions.
In order to guarantee the order of messages for some kind of messages, we need to use a record key.
All the messages with that record key will go through the same partition.
You could take a look at the article named Create a Kafka Producer with a Key (using Java).
Each partition could have 0 or more replicas (for high availability). Only one partition is used for read/write (the leader), the other are just replications. The replica takes over as the new leader if somehow the leader fails.